GPU驱动及CUDA安装流程介绍
GPU 驱动及 CUDA 安装流程介绍
- 安装前准备工作
- 确认GPU型号和操作系统版本
- 准备gpu驱动和CUDA软件包
在 nvidia 官网进行驱动包下载
GPU 驱动下载链接:https://www.nvidia.cn/Download/index.aspx?lang=cn
linux 系统均选择 Linux 64-bit
CUDA Toolkit 选择最新版本
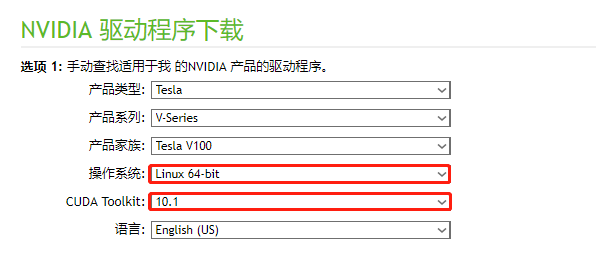
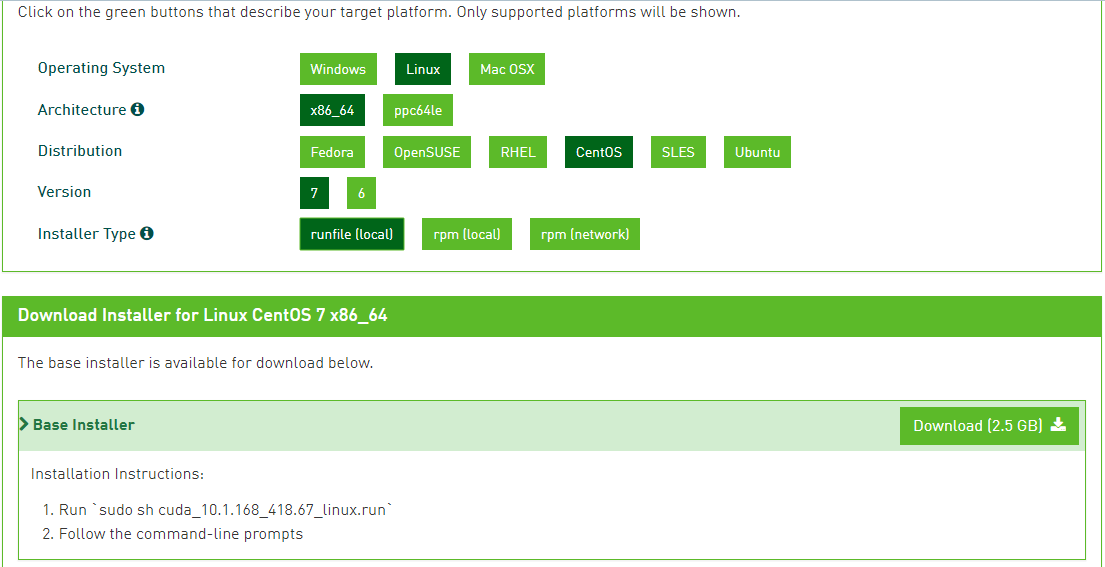
CUDA 下载链接:https://developer.nvidia.com/cuda-downloads
选择合适的操作系统版本进行下载。
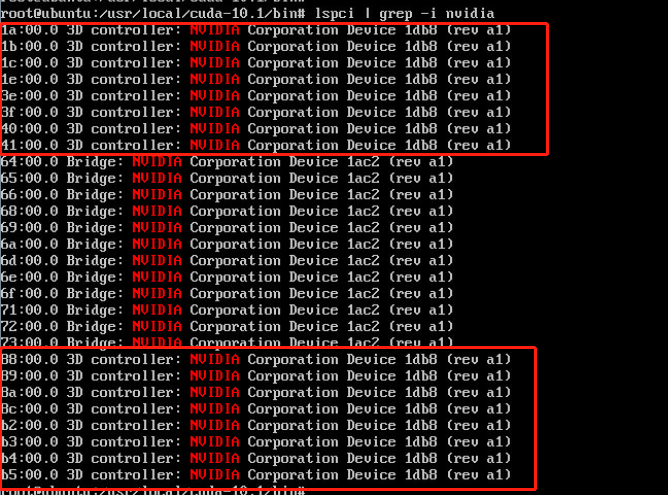
- 检查服务器GPU识别情况
安装 GPU 驱动之前需要在操作系统下查看 GPU 卡是否能够完全识别, 如不能识别需要进行重新插拔、对调测试等步骤进行硬件排查。
#确保可以查看到所有的 GPU
# lspci | grep -i nvidia
- 老版本软件包卸载
a) 若安装过其他版本的 GPU 驱动或 CUDA,请先卸载。
GPU 驱动卸载方法:
# /usr/bin/nvidia-uninstall
CUDA 卸载方法:
# /usr/local/cuda-X.Y/bin/cuda-uninstaller
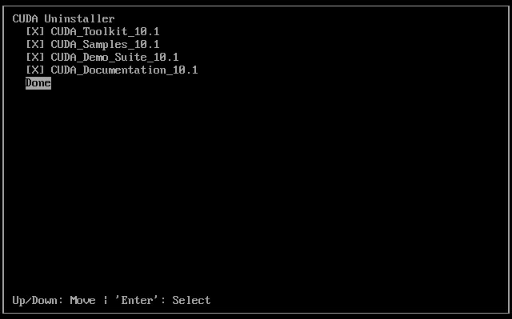
或(老版本卸载方法)
# /usr/local/cuda-X.Y/bin/uninstall_cuda_X.Y.pl
- 安装gcc、g++编译器
GPU 驱动安装时需要 gcc 编译器。
cuda 安装 samples 测试程序进行 make 时需要 g++,但安装 cuda 软件包时不需要。
CentOS 7:
#检查版本
gcc -v
g++ -v
#软件包安装
# yum install gcc
# yum install gcc-c++
SUSE:
#检查版本
gcc -v
g++ -v
#软件包安装
zypper in gcc
zypper in gcc-c++
Ubuntu:
#检查版本
# gcc -v
# g++ -v
#软件包安装
# apt-get install gcc
# apt-get install g++
# apt-get install make
#软件包检查
# dpkg -l gcc
# dpkg -l g++
# dpkg -l make
- 安装kernel-devel和kernel-headers软件包
CentOS 7
# yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r)
Ubuntu:
#Ubuntu 可以不安装,也可以从阿里镜像站或网易镜像站下载,需注意内核版本。
SUSE:
zypper install kernel-source-$(uname -r) #只安装这一个即可
zypper install kernel-default-devel-$(uname -r)
- 禁用系统自带的nouveau模块
检查 nouveau 模块是否加载,已加载则先禁用
# lsmod | grep nouveau

CentOS 7:
#没有 blacklist-nouveau.conf 文件则创建
# vim /usr/lib/modprobe.d/blacklist-nouveau.conf blacklist nouveau
options nouveau modeset=0
执行如下命令使内核生效(需要重启服务器后才可真正禁用 nouveau)
# dracut -force
Ubuntu:
vi /etc/modprobe.d/blacklist.conf
在文本最后添加以下内容:
blacklist nouveau
options nouveau modeset=0
保存退出,执行以下命令生效:
# update-initramfs -u
重启操作系统
- 修改系统运行级别为文本模式
GPU 驱动安装必须在文本模式下进行
CentOS 7
# systemctl set-default multi-user.target
Ubuntu:
systemctl stop lightdm
systemctl disable lightdm
SUSE:
vim /etc/inittab
修改
id:5:initdefault:
为
id:3:initdefault:
- 重启系统后,使禁用nouveau模块配置生效并进入文本模式

- GPU驱动安装
- root用户下进行GPU驱动
# chmod +x NVIDIA-xxx.run
# ./NVIDIA-Linux-x86_64-390.46.run --no-opengl-files --ui=none --no-questions --accept-license
- 配置GPU驱动内存常驻模式
GPU 驱动模式设置为常驻内存:
# nvidia-smi -pm 1
设置开机自启动
vim /etc/rc.d/rc.local
在文件中添加一行
nvidia-smi -pm 1
赋予 /etc/rc.d/rc.local 文件可执行权限
# chmod +x /etc/rc.d/rc.local
#若无 /etc/rc.d/rc.local,也可修改
vim /etc/rc.local
chmod +x /etc/rc.local
#SUSE
vim /etc/init.d/after.local #没有就新建
nvidia-smi -pm 1
chmod +x /etc/init.d/after.local
- nvidia-smi
安装完 GPU 驱动后,可以使用 nvidia-smi 命令进行 GPU 状态查看及相关配置。
- CUDA安装
- 安装CUDA
安装 CUDA 时需注意,如果之前安装过 GPU 驱动,安装 CUDA 时就不要再选择 GPU 驱动安装了。
chmod +x cuda-xxx.run
./cuda-xxx.run --no-opengl-libs
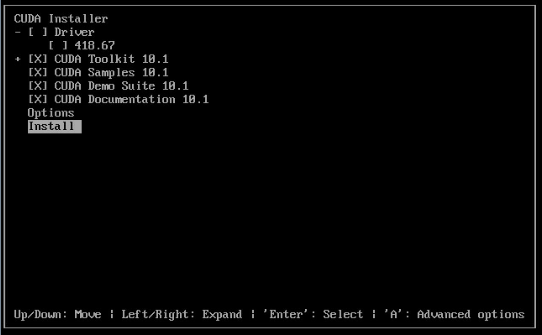
新版本 CUDA 安装界面:
注意 Driver 选项,表示是否安装 GPU 驱动,如果之前已经安装了 GPU 驱动,这里不要再勾选。
旧版本 CUDA 安装:
[root@ localhost ~]# ./cuda-xxx.run --no-opengl-libs
… … … …
… … … … #### 约定条款,此处忽略打印
-----------------
Do you accept the previously read EULA?
accept/decline/quit: accept
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 387.26?
(y)es/(n)o/(q)uit: n ### 若已经安装过驱动,则此处不需再安装
Install the CUDA 9.2 Toolkit?
(y)es/(n)o/(q)uit: y
Enter Toolkit Location
[default is /usr/local/cuda-9.1]: #### 回车,默认
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
Install the CUDA 9.2 Samples?
(y)es/(n)o/(q)uit: y ## 安装 samples
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-9.2/bin
To uninstall the NVIDIA Driver, run nvidia-uninstall
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-9.2/doc/pdf for detailed information on setting up CUDA.
Logfile is /tmp/cuda_install_62403.log
#### 安装完成,如果安装失败,查看上述提示日志信息。
- 配置环境变量
添加到 /etc/profile 文件中,对所有用户生效
# vim /etc/profile
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
# source /etc/profile
测试 cuda 安装是否正确,环境变量是否识别成功
# nvcc -V
- CUDA samples程序测试
- BandwidthTest
BandwidthTest 测试 GPU 卡与主机 server、GPU 与 GPU 卡之间的显存带宽,测试结果中 Host to Device Bandwidth 和 Device to Host Bandwidth 分别为主机 server 至 GPU 卡和 GPU 卡至主机 server 的显存带宽,Device to Device Bandwidth 测试的是 GPU 卡之间的显存带宽。
编译、测试
# cd /usr/local/cuda/samples/1_Utilities/bandwidthTest/
# make
# ./bandwidthTest
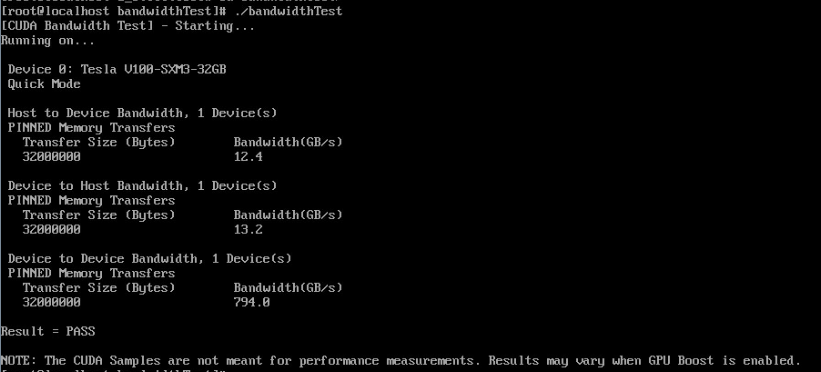
测试结果参考
Host to Device Bandwidth 和 Device to Host Bandwidth 两项数值在 12,000MB/s-13,000MB/s 之间
Device to Device Bandwidth 测试显存带宽,该值根据 GPU 显存硬件配置而异,下表列出个 GPU 理论显存带宽,实测值在理论值 70% 以上即认定状态正常。
GPU 型号 | 显存带宽理论值 |
P100-PCIE-12GB | 548GB/s |
P100-PCIE-16GB/P100-SXM2-16GB | 732GB/s |
P40 | 346GB/s |
P4 | 192GB/s |
V100-PCIE/SXM2 全系列 | 900GB/s |
- P2pBandwidthLatencyTest
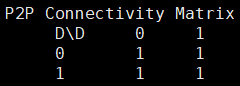
P2pBandwidthLatencyTest 测试结果为 GPU 卡之间的带宽,在进行带宽取值时,一般取 enable 对应的值即矩阵值 =1 时对应的结果。举例说明如下:
D\D 对应的每行、每列表示 GPU0、GPU1、GPU2。则 GPU0 与 GPU1 是 P2P 的,即代表为 1,GPU0 与 GPU2 不是 P2P 的,即代表为 0。
编译、测试
# cd /usr/local/cuda/samples/1_Utilities/p2pBandwidthLatencyTest/
# make
# ./p2pBandwidthLatencyTest
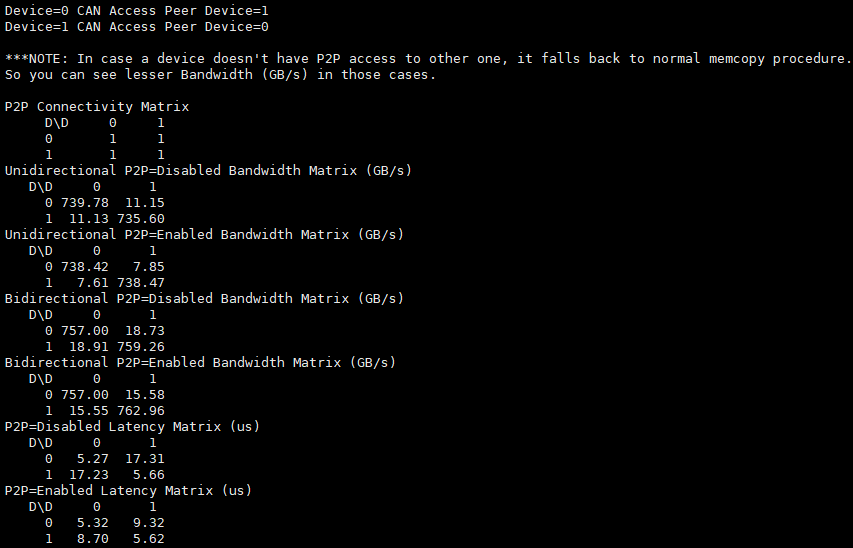
输出关注部分(以机器实际测试结果为准,下图为示意图。数据分析及合格标准见后页)
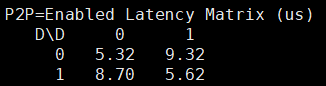
以 Bidirectional P2P=enable 的带宽数据和 P2P=enable 的延迟数据为准
分别查看互联拓扑、双向带宽、延迟时间。

测试结果参考:
互联矩阵中,有 1 标记即表示 GPU 间有 P2P 访问支持功能,0 即无
根据 GPU 硬件版本不同,带宽和延迟存在差异,按照 GPU 型号数据总结如下
GPU 型号(带宽实测均值) | 矩阵值 1 | 矩阵值 0 |
PCIE GPU | 22-26GB/s | 17-20GB/s |
P100-SXM2(NVLINK1.0) | 35-38GB/s | 17-20GB/s |
V100-SXM2(NVLINK2.0) | 90-95GB/s 和 45-48GB/s | 15-20GB/s |
GPU 型号(延迟实测均值) | 矩阵值 1 | 矩阵值 0 |
PCIE GPU | ≤10us | ≤20us |
P100-SXM2(NVLINK1.0) | ≤10us | ≤20us |
V100-SXM2(NVLINK2.0) | ≤10us | ≤20us |
- BatchCuBlas
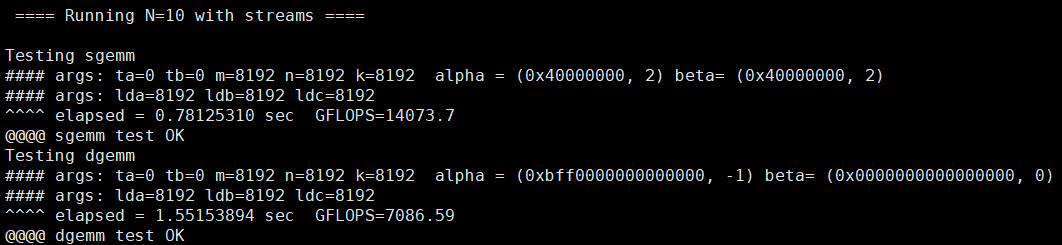
BatchCuBlas 为 GPU 浮点运算能力测试、加压。测试包括 sgemm(测试单精度浮点计算能力)和 dgemm(双精度)两部分,关注 GFLOPS 测试值。测试值达到理论值 90% 以上认定状态正常。
编译、测试
在测试命令中 m、n、k 值可调整,一般 GPU 缓存大小 16G 时可选 8192,是个经验值。32G 的测试如果 8192 可以测试出来正常数值也可以不改。
在测试命令中,使用 --device=1 参数指定测试 ID 号为 1 的 GPU 卡,默认测试 ID 号为 0 的 GPU 卡。
# cd /usr/local/cuda/samples/7_CUDALibraries/batchCUBLAS/
# make
# ./batchCUBLAS -m8192 -n8192 -k8192 ## 默认测试 ID 号为 0 的 GPU 卡
# ./batchCUBLAS -m8192 -n8192 -k8192 --device=1 ## 指定测试 ID 号为 1 的 GPU 卡
测试结果中,我们只关注 Running N=10 with streams 部分,分为单精度和双精度测试